PythonとLINE APIとHerokuでBOTを作る【Python編】
目次
LINE BOTを作るにあたって
普段はRubyを書いているのですが、Pythonで機械学習をしたいと思いたち、 第一段階としてとりあえずユーザーのLINEの言葉に反応してくれるBOTを作りました。
もっと詳しく一言で言うと PythonとHerokuとLINEのMessagingAPIを用いて、ユーザーの言葉に反応して、該当するニュースをyahoo!ニュースからスクレイピングしてくれるLINE BOTを作ります。
今回はPythonのソースコードを中心にまとめたいと思います。
環境
Python 3.6.6 LINE Messaging API Heroku
LINEのMessaging APIとHerokuのアカウントを取得しておきます。 別記事で解説できればと思いますが、一旦私が環境設定で参考にしたサイトを貼っておきます。 Anaconda で Python 環境をインストールする PythonでLINE Botを作って見よう!
またコードは公式のGitHubを参考にしています。 https://github.com/line/line-bot-sdk-python
LINE BOT完成状態
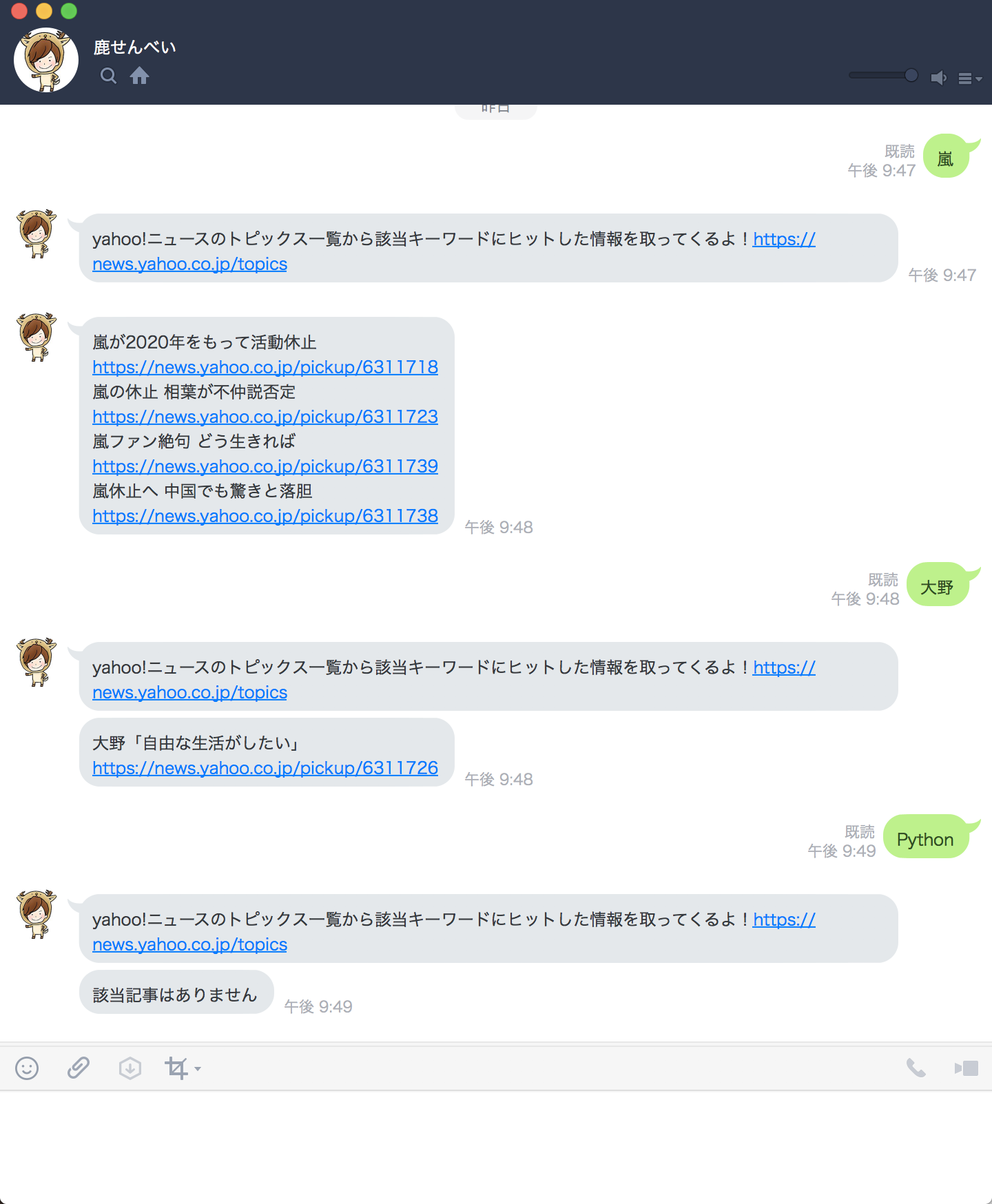
大まかな流れ
- LINEでユーザーが文字を入力
- LINEで設定したWebhookのURLにリクエストが走る(今回の場合、HerokuでデプロイしたURL)
- リクエストを受けてHerokuが起動
- Herokuの中身のPython(main.py)が処理を始める
- 続いてscrape.pyが処理を実行し、yahoo!ニュースへのスクレイピングを開始する
- 該当記事があれば記事を、なければ「なかったよ!!」という文言を返す。
- scrape.pyの結果がリクエストの結果として返され、LINEに表示される。
ファイル構成
line_bot ├ main.py ├ scrape.py ├ Procfile ├ runtime.txt └ requirements.txt
普段Railsでアプリケーションを作成するときは、いきなりわしゃーっとファイルがあるので、少し心配になりますが、ファイルはこれだけで大丈夫です。
それぞれの中身を見ていきましょう。
main.py
import urllib.request
import os
import sys
import json
import scrape as sc
from argparse import ArgumentParser
from flask import Flask, request, abort
from linebot import (
LineBotApi, WebhookHandler
)
from linebot.exceptions import (
InvalidSignatureError
)
from linebot.models import (
MessageEvent, TextMessage, TextSendMessage,
)
app = Flask(__name__)
channel_secret = os.getenv('LINE_CHANNEL_SECRET', None)
channel_access_token = os.getenv('LINE_CHANNEL_ACCESS_TOKEN', None)
if channel_secret is None:
print('Specify LINE_CHANNEL_SECRET as environment variable.')
sys.exit(1)
if channel_access_token is None:
print('Specify LINE_CHANNEL_ACCESS_TOKEN as environment variable.')
sys.exit(1)
line_bot_api = LineBotApi(channel_access_token)
handler = WebhookHandler(channel_secret)
@app.route("/callback", methods=['POST'])
def callback():
signature = request.headers['X-Line-Signature']
body = request.get_data(as_text=True)
app.logger.info("Request body: " + body)
try:
handler.handle(body, signature)
except InvalidSignatureError:
abort(400)
return 'OK'
@handler.add(MessageEvent, message=TextMessage)
def handle_message(event):
word = event.message.text
result = sc.getNews(word)
line_bot_api.reply_message(
event.reply_token,
TextSendMessage(text=result)
)
if __name__ == "__main__":
port = int(os.getenv("PORT", 8000))
app.run(host="0.0.0.0", port=port)
scrape.py
from bs4 import BeautifulSoup
import urllib.request
import json
import requests
url = 'https://news.yahoo.co.jp/topics'
ua = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) '\
'AppleWebKit/537.36 (KHTML, like Gecko) '\
'Chrome/67.0.3396.99 Safari/537.36 '
def getNews(word):
req = urllib.request.Request(url, headers={'User-Agent': ua})
html = urllib.request.urlopen(req)
soup = BeautifulSoup(html, "html.parser")
main = soup.find('div', attrs={'class': 'topicsMod'})
topics = main.select("li > a")
count = 0
list = []
for topic in topics:
if topic.contents[0].find(word) > -1:
list.append(topic.contents[0])
list.append(topic.get('href'))
count += 1
if count == 0:
list.append("記事が見つかりませんでした!!")
result = '\n'.join(list)
return result
Procfile
web: python main.py
requirements.txt
Flask==0.12.2
line-bot-sdk==1.5.0
beautifulsoup4==4.7.
soupsieve==1.6.1
urllib3==1.24.1
runtime.txt
python-3.6.6
簡単な解説
main.py
import urllib.request
import os
import sys
import json
import scrape as sc
from argparse import ArgumentParser
from flask import Flask, request, abort
from linebot import (
LineBotApi, WebhookHandler
)
from linebot.exceptions import (
InvalidSignatureError
)
from linebot.models import (
MessageEvent, TextMessage, TextSendMessage,
)
この部分は必要な物を呼び出している部分ですね。 特筆すべきことはありません。
channel_secret = os.getenv('LINE_CHANNEL_SECRET', None)
channel_access_token = os.getenv('LINE_CHANNEL_ACCESS_TOKEN', None)
if channel_secret is None:
print('Specify LINE_CHANNEL_SECRET as environment variable.')
sys.exit(1)
if channel_access_token is None:
print('Specify LINE_CHANNEL_ACCESS_TOKEN as environment variable.')
sys.exit(1)
line_bot_api = LineBotApi(channel_access_token)
handler = WebhookHandler(channel_secret)
ここでは主にAPIのキーの設定を行います。
ここで気をつけたいのがLINE_CHANNEL_SECRETとLINE_CHANNEL_ACCESS_TOKENの部分です。
色々なサイトを参考にしてLINEBOTを作ろうとする人が大半だと思いますが、 このキーの部分の記述がサイトによって結構異なっています。
するとどういうことが起こるのか。
herokuのconfigの設定とここの記述が食い違ってくるのです。 実際私はLINE_BOT_CHANNEL_SECRETやYOUR_CHANNEL_SECRETなど好き勝手設定していました。
LINEBOTがなぜか動作しない場合、ターミナル上で
$ heroku config
を実行して、setしているキーとmain.pyで呼び出しているキーの名前があっているか確かめて見ると良いかもしれません。
キーの中身ではなく、キーの名前が違うというどうしようもない間違いも経験ですね。
@app.route("/callback", methods=['POST'])
def callback():
signature = request.headers['X-Line-Signature']
body = request.get_data(as_text=True)
app.logger.info("Request body: " + body)
try:
handler.handle(body, signature)
except InvalidSignatureError:
abort(400)
return 'OK'
@handler.add(MessageEvent, message=TextMessage)
def handle_message(event):
word = event.message.text
result = sc.getNews(word)
line_bot_api.reply_message(
event.reply_token,
TextSendMessage(text=result)
)
if __name__ == "__main__":
port = int(os.getenv("PORT", 8000))
app.run(host="0.0.0.0", port=port)
すみません。 この辺りの理解が曖昧です。なので解説は控えておきます。
def handle_messageの部分で scrape.pyの結果をLINEの返信のメッセージとする処理を行なっています。
scrape.py
url = 'https://news.yahoo.co.jp/topics'
ua = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) '\
'AppleWebKit/537.36 (KHTML, like Gecko) '\
'Chrome/67.0.3396.99 Safari/537.36 '
ここでスクレイピングしたいサイトのURLを指定します。 uaの中身はブラウザによる違いをなくすためになるようです。
def getNews(word):
req = urllib.request.Request(url, headers={'User-Agent': ua})
html = urllib.request.urlopen(req)
soup = BeautifulSoup(html, "html.parser")
main = soup.find('div', attrs={'class': 'topicsMod'})
topics = main.select("li > a")
ここがyahoo!ニュースのページから記事を探すという処理を行なっている部分になります。
soup = BeautifulSoup(html, "html.parser")によりHTMLを取得します。
main = soup.find('div', attrs={'class': 'topicsMod'})
topics = main.select("li > a")
mainで取得範囲を絞り込み、topicsで取得したい部分(aタグ)を指定します。
count = 0
list = []
for topic in topics:
if topic.contents[0].find(word) > -1:
list.append(topic.contents[0])
list.append(topic.get('href'))
count += 1
if count == 0:
list.append("記事が見つかりませんでした!!")
result = '\n'.join(list)
return result
一番初めの画像のように「嵐」という検索ワードなど複数の検索結果がある場合のために for文で処理します。
もし一つも見つからなければ"記事が見つかりませんでした"を返します。
Procfile
web: python main.py
私はProcfileのことをProfileだと思って設定していてハマりました。 何故かLINEBOTが動作しない場合、ファイル名を目を皿のようにして確認して見ると解決することがあります。
requirements.txt
Flask==0.12.2
line-bot-sdk==1.5.0
beautifulsoup4==4.7.
soupsieve==1.6.1
urllib3==1.24.1
runtime.txt
python-3.6.6
上記2つのtxtファイルは自分のバージョンとの齟齬がなければここは大丈夫です。
ハマったポイント
文中にもいくつか自分のつっかえたポイントを記述しておきましたが、一番ハマったポイントはHerokuのDynoを設定していなかったためにLINEのWebhookの接続がうまくいかなかったところです。
簡単なようでいて、PythonもHerokuもLINEAPIも初めて触ったので、一筋縄では行きませんでしたね。
今後の展望
次にやりたいことは機械学習を用いて、ユーザーの投稿した画像を認識するBOTにしたいと思います。
アドバイス等々いただければ励みになりますので、どうぞよろしくお願いします!!